The new TV program featuring John Edward,
one of the currently popular "cold readers" who is
"speaking with the dead," has brought the JREF a storm
of inquiries in recent weeks. This vaudeville act, which made
fortunes for Anna Eva Faye and the Davenport Brothers in the
early 1900s, has now embraced television with great success,
supported by such perceptive TV hosts as Larry King and Montel
Williams, who know an attractive bamboozlement when they see
it. When Edward, along with Sylvia Browne, James Van Praagh,
and veteran John Anderson, emerged recently to beguile the public,
we had a resurgence of interest in what the famous Fox sisters
started way back in 1848 and became known as spiritualism.
The process of "cold reading" can be rather subtle and clever, though frankly I don't see in any of the current crop of readers the resilience or inventiveness that I've observed in such performers as Doris Stokes or Doris Collins, in the UK. I describe the act on this web page. We just cannot answer every inquiry individually, and I direct you to click on "The Randi Files" and then on "The Art of Cold Reading." My "Encyclopedia of Claims, Frauds and Hoaxes of the Occult and Supernatural" also has an entry on the subject.
........................................................................................
Our good friend Eric Krieg sent us the following article by Tom Napier, who has graciously given us permission to publish it here. (I have taken the liberty of inserting a few notes in order to clarify some points). It expresses rather well the situation in regard to the standards that the JREF has established for the $1,000,000 challenge. Tom Napier has a BS in Physics, a Masters in Electronics, and lots of Common Sense. His work experience includes stints at the European Space Technology Center, and CERN (European Laboratory for Particle Physics), and he is a founder of PHACT, the Philadelphia Association for Critical Thinking.
Are the Randi Tests Fair?
by Tom Napier
It is often argued that supernormal powers
are so sporadic in their operation that they cannot be tested
by the type of experiment required by James Randi for the JREF
$1,000,000 award. I would like to look at this contention from
the point of view of a physicist with some knowledge of statistics.
I should emphasize that, while I was present as an observer during
the unsuccessful demonstration of the existence of the human
energy field sponsored by James Randi and Bob Glickman in Philadelphia
in November 1996, I have no direct connection with Randi or JREF
and I certainly cannot make any representations on their behalf.
From my reading and my own observations it appears that the object of a Randi test is to distinguish with high probability between people who actually have the ability they claim and those who do not. The first decision which Randi must make is whether the claimed ability qualifies for the award, that is, does it lie outside the range of normal human physiology or beyond the laws of science as they are presently understood. No one disputes that one can bend a spoon with one's hands, no prizes for that. Bend one by looking at it as it sits on a table and you would qualify. The ability also has to be verifiable in some way. You might claim to feel cold every time a ghost walks through the room but, unless there is an independent way of determining the presence of a ghost, your claim is meaningless.
Note by Randi: before any of that takes place, we have to (a) get the claimant to state clearly what he/she can do, under what conditions, and with what accuracy. This, as Andrew Harter at the JREF will verify, is often the very hardest thing for us to ascertain. Then, as stated in the rules, we have to (b) conduct a preliminary test - with much less stringent conditions and much more attainable percentages of success. Please also note that to date, no one has successfully completed a preliminary test.
Once it has been agreed that an ability is
supernormal and can be tested it is necessary to devise a suitable
test protocol. This is always designed in conjunction with the
person being tested. It is they after all who are making claims
about what they can do. There must be some target performance
which, if achieved, shows that the ability probably exists. There
should be a second target which, if not achieved, shows that
the ability does not exist. Between the two there will be a fuzzy
area in which we cannot say for sure whether or not the ability
exists. The test target must be set so that it can be easily
achieved by the truly supernormal but is unlikely to be achieved
by chance by someone without any abnormal ability. After all,
if the probability of getting a passing score were, say, 1% then
the Randi award would have been collected ages ago, even if no
one had any paranormal powers whatsoever. The target must be
such that probability of getting a passing score by chance is
truly insignificant, perhaps less than one in a million. (Even
with those odds, there is a 1% chance that one of the first 10,000
applicants would achieve a passing score by pure chance.)
"Not fair," cry the proponents, "these gifts don't work perfectly. You have to cut us some slack." On the other hand, claimants tend to be absurdly optimistic. Before being tested astrologers and dowsers have claimed 100% accuracy; it would be reasonable to hold them to the performance they claim. When Randi and Glickman tested a therapeutic touch practitioner she set her own standard. She showed she could distinguish between two people's energy fields with 100% accuracy - when she could see the subjects. When tested under exactly the same conditions, but with the subjects hidden from view, she scored 11 out of 20, a result entirely consistent with random guessing. A score of 18 or over would have been accepted as qualifying her for the full, money on the table, test.
Note by Randi: Well, not quite yet. Twenty trials were not quite enough for a preliminary test, which this was. But the practitioner, against her initial agreement with us, simply refused to go on with it.
In every test I've heard of, the experimenters
have allowed a much less ambitious target to be used as the criterion
of success. Far from making things hard, experimenters go out
of their way to make things easy. They don't want to give the
claimants the slightest excuse for failure. Still, you have to
draw the line somewhere. I sometimes claim to have a gift to
predict the sex of an unborn child. It is a powerful gift but
it is right only 50% of the time. Why does that get a laugh from
the audience? Because one can do just as well by guessing. Being
right half the time proves nothing, precisely because the odds
of guessing right are also 50%. Does that mean that if someone
claims an ability which works only half the time, we can never
prove it true? The answer is no, we just have to work out a test
protocol where the probability of correct guessing is much less
than 50%.
Let me give an example. We are going to test
a dowser who can detect gold. If he's a typical dowser he has
never carried out a scientific test of his ability yet he claims
a 100% success rate. He probably means that whenever he knows
gold is present he gets a dowsing reaction 100% of the time.
The important thing to find out is whether he can detect the
presence of gold when neither he nor anyone else present knows
where the gold is. In a typical test a number of identical containers
such as plastic 35 mm film cans are used. One contains a piece
of gold padded with cotton wool. The others contain equal weights
of lead, similarly padded. Usually the test starts with a confirmation
that the conditions are suitable for dowsing. The subject is
told which can contains the gold and demonstrates his ability
to detect it. This test can be repeated several times; the expected
result is 100% success. The containers are then shuffled, out
of sight of the subject and the witnesses. Now all the dowser
has to do is to repeat the former test. The only difference is
that now he doesn't know which is the correct target unless his
dowsing ability tells him. Of course he might hit on the gold
by accident even with no dowsing ability. If there are five targets
even a giftless dowser has a 20% chance of scoring a hit. That's
why the test must be repeated many times. The guesser will continue
to get about one hit in five attempts, the real dowser should
do much better.
Regrettably, it is necessary for the test
to be designed to make cheating ineffective. Thus we must switch
the gold from can to can between tests, just in case there is
some way of distinguishing the correct can from external marks.
It is also important that no one in the test room knows which
is the correct target, in case they give unconscious clues to
the dowser. This doesn't mean that the dowser intends to cheat;
people can use helpful information without knowing they are doing
so. The test protocol must eliminate any possibility of such
information being available.
If we carry out the test twice, the chance of getting hits on
both tests by accident is 0.2 times 0.2 or 4%. That's still quite
high. To beat the one in a million level would require nine successful
tests. Still, our 100% accurate dowser should be able to do this
in an hour, and walk off a million dollars richer.
So how do we test the less confident dowser,
the one who claims a 50% success rate? We must increase the number
of tests until the cumulative probability of guessing drops below
the one in a million level. The easiest way of doing this is
to increase the number of cans used in each test. If we used
only two cans, both the random guesser and the 50% successful
dowser would show an identical success rate. With five cans the
difference between the guesser's 20% success rate and the dowser's
50% rate is not great. By using 100 cans in each test we would
reduce the guesser's success rate to 1%, and the dowser should
still be right half the time.
This test must still be repeated many times.
We have to pick the number of tests such that there is some number
of total hits which the real dowser should beat nearly all the
time but which the random guesser will achieve only once in a
million trials. For example, repeating this test twenty times
would give the real dowser an average score of ten. In practice
his actual score can vary over a wide range. However, it can
be shown that he will score six or better on 47 trials out of
48 and five or better on 168 trials out of 169. If we pick a
threshold score in the region of five or six hits, we are not
too likely to fail a real 50% accurate dowser. The random guesser
would get one hit in about 11% of such trials but has a rapidly
falling probability of getting more than one hit. His probability
of getting four or more hits is one in 731,101 trials, not far
short of our one in a million criterion. The guesser will hit
five or more times about once in 29 million trials. Thus taking
five hits in twenty tests as our threshold virtually eliminates
chance success and is still fair to our 50% accurate dowser.
I've gone on at some length with this example
to show that it is possible, with some calculation, to devise
a fair test even for abilities which don't work every time. I'm
sure James Randi has access to better statisticians than I and
is just as able (and willing) to design fair tests for intermittent
abilities.
©2000, Tom Napier
........................................................................................
Okay, here's the Vitruvian Man Puzzle solution . . .
The reaction to this was very heavy, much
to our delight. I said at the very beginning that it was a trick
question. A number of people not only solved that, but came up
with a complete set of three answers - for there are three correct
answers!
The original question use the word "revolution." Many persons didn't notice that, and assumed that it was congruent with "rotation." Not so. Webster's Dictionary seems just a bit loose on the differences between these words, but technically a revolution consists of a body turning around another one, as when the Earth revolves about the Sun, once every year. The word "rotate" refers to a body turning around on its own axis, illustrated by the manner in which the Earth spins about on its own axis once a day. If we accept these strict definitions, then the simple answer to our inquiry, is "one revolution." The dizzy little man goes through one revolution, while rotating at the same time. (A few readers pointed out that our Moon, though from our point of view, always presents the same face to us and thus appears not to rotate, actually does rotate once every month. Did that ever occur to you?)
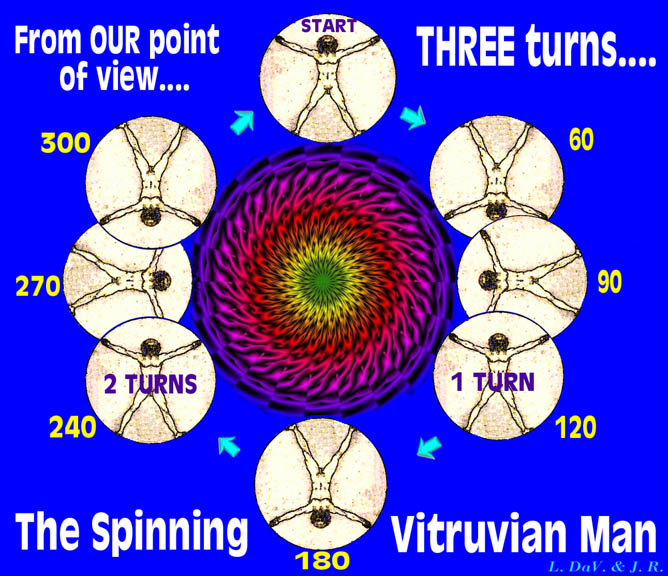
But how many rotations does he make? Well, the diagrams that accompany this explanation should make it quite clear. It's a matter of relativity. To us, the spectators looking down on this strange drama, the Vitruvian Man starts out at the top of the larger wheel with his feet down and his head up - from our point of view. One-third of the way (120°) around the larger wheel, we see that his feet are now "down" and his head is now "up" again, and two-thirds of the way (240°) through his revolution, we see the same circumstance again. When he is again "standing upright," he has completed three rotations, relative to us.
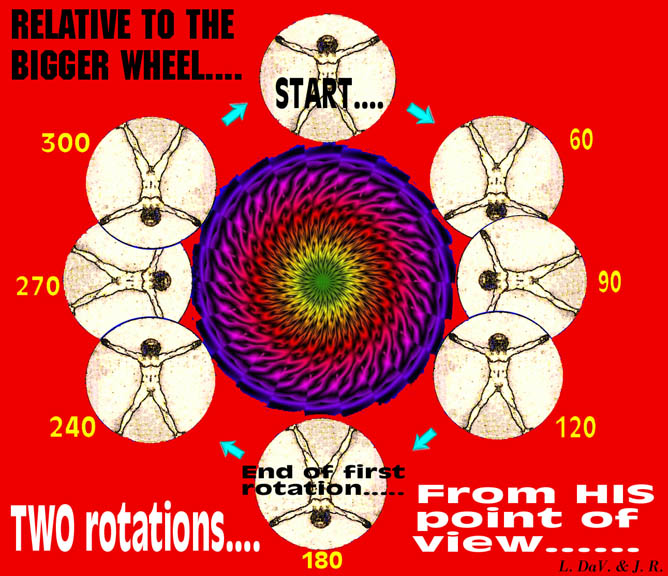
However, consider it from the point of view
of the long-suffering chap himself. At the top, starting his
voyage, he notes that his feet are adjacent to the larger wheel.
He begins to spin - to rotate - and when he again notices his
feet adjacent to the larger wheel, he is halfway through his
revolution. When his same position relative to the wheel occurs
again, he has completed one revolution, and is firmly convinced
that he has rotated only twice.
In summary, the Vitruvian Man makes only one revolution, we see
him make three rotations - about his own navel! - and he himself
thinks he made two rotations. As you see, it is a matter of strict
definitions and of relativity - but not Relativity.
We sincerely thank all of you who took an interest in this problem.
And, you may well be ready for another. This one was suggested
to us by correspondence, and it's much less involved. (But NEXT
week, we'll really strain your wetwear! Start thinking about
wine glasses....)
Problem: consider the following algebraic expression . . .
(a-x)×(b-x)×(c-x)×(d-x) . . . . .×(z-x)=
(All the letters of the alphabet are used, all 26.)
Question: what is the most concise way in which we can express this product? You can use any mathematical notation you wish, but try to make it transferable/translatable by our differing computer systems and/or software.
BTW: Thanks to the folks who made us aware of the SNAFU in our system last week that mis-identified the previous week's archive file as, "htnl" rather than as "html." Those of you who may have been looking for former puzzle information, might have been confounded by this.
I am now assured by my clever Web-person that this has been fixed and you can go back and look at the original material now in "Randi's Opinion Archive" (or you can just click here).
